open(“fila_path”, mode=”x”)
打开文件的几种模式:
r:常见的只读模式w:也很常见的写模式,但是会覆盖a:追加模式,不会覆盖,会在原有基础上写x:通俗解释就是【只会在文件不存在时创建文件并写入,如果文件存在则会直接报错】
使用x模式需要注意最好提前检查路径是否存在。在不希望现有结果被覆盖的情况下比较好用(比如怕自己手抖运行了已经修改了的或者测试版的程序,结果直接覆盖了重要结果)。
slot
python的类的实例,通常情况下其成员变量是通过字典来存储的,比如我们访问一个实例的__dict__变量来获取这些内容。
但是这样存在的问题是,字典的存储,是要浪费空间的,甚至,极端情况下,字典的key占用的空间比value占用的都要多,该怎么办?
同时,python作为一个动态语言,是可以随时往一个实例里添加成员变量的,但是这其实在很多情况下不是个好主意,那么如果我们想要规定一个类只能有这几个成员变量,该怎么办?
这时候,涉及的就是python的__slots__的用法。
简单来说,__slots__的作用是规定了一个类的成员变量的最多也就是slot里的这些变量名,不能更多了,但是可以更少。
举例来说,我们可以这样定义:
1
2
3
4
5
class Student(object):
__slots__ = ("sid", "name")
def __init__(self, sid, name):
self.sid = sid
self.name = name
这时候,我们如果初始化一个Student的实例,然后访问它的__dict__就会报错,同时如果我们的代码写成这样,也会直接报错:
1
2
3
4
5
6
class Student(object):
__slots__ = ("sid", "name")
def __init__(self, sid, name):
self.sid = sid
self.name = name
self.num = 1
会在第三行报错,因为num这个成员变量名不在__slots__中。
dataclass
如果我们有一个数据结构,但是没什么方法要实现,该怎么做?举例来说,假设,我们有一个Student类,它只有sid和name两个属性,该怎么办?
一种方法是这样:
1
2
3
4
class Student(object):
def __init__(self, sid, name):
self.sid = sid
self.name = name
还有一种方法是
1
2
3
4
@dataclass
class Student(object):
sid: str
name: str
用后一种方法的好处包括:
- Python风格(NamedTuple你反思一下)
- 自带比较好的
__repr__函数,输出好看 - 自带
__eq__函数,比较方便 - 通过
frozen参数轻易实现immutable特性 - 其他可以通过参数控制的特性,参见https://docs.python.org/3/library/dataclasses.html
其实还有第三种方法——使用NamedTuple
1
2
3
from typing import NamedTuple
Student = NamedTuple("Student", [("sid", int), ("name", int)])
我不喜欢这种方式最大的理由之前提过——是NamedTuple不够python风格。我们可能更希望一个类是以class开头,并且每个成员变量的类型通过冒号指定(这一点纯粹是个人喜好)。其实NamedTuple和dataclass很多普通情况下可以相互替代,既然如此,我更推荐用dataclass。另外,关于空间占用问题,NamedTuple的确要省点地方,毕竟是基于Tuple的,不过我猜测dataclass通过slot参数也能控制。
zip(strict=True)
需python3.10及以上
python 3.10之前的zip是不会检查参数里的多个列表(iterable)是否match的,但是如果python3.10之后可以通过strict参数来控制
举例来说:
1
2
3
4
5
a = [1, 2, 3]
b = [1, 2]
print(list(zip(a, b)))
print(list(zip(a, b, strict=True)))
第一个zip的输出结果是[(1, 1), (2, 2)],这个结果其实很多时候不是我们想要的,或者说很容易漏掉检查
第二个zip会直接报错,因为长度不匹配,报错信息如下:
Traceback (most recent call last): File “
", line 1, in ValueError: zip() argument 2 is shorter than argument 1
还很细心地提示了第二个参数比第一个参数短☺
try 多个error
写try…except…的时候,except后可以添加多个错误类型,从而对着多种错误统一处理,伪代码类似这样:
1
2
3
4
5
6
7
8
try:
do_something()
except ErrorType1, ErrorType2, ErrorTupe3:
one_error_handling()
except ErrorType1, ErrorType2, ErrorTupe3:
another_error_handling()
except Exception:
common_error_handling()
itertools.count
有的时候我们记录循环的次数,但是却不知道最后要循环多少次,这时候我们的一种写法是
1
2
3
4
5
6
7
count = 0
while 1:
count += 1
result = do_something()
print(f"result_{count} = {result}")
if not result:
break
典型场景例如分块下载文件、分拆大文件为多行等等。
这里不适合用range是因为不知道大小(例如不知道大文件的行数),不适合用enumerate是因为没有什么东西来枚举。
但是如果你不喜欢while的写法,或者觉得单独操作count有点烦,那么可以利用itergools.count改成这样:
1
2
3
4
5
6
import itertools
for count in itertools.count():
result = do_something()
print(f"result_{count} = {result}")
if not result:
break
这样能更简洁一些。
pandas导出csv兼容问题
在pandas的dataframe导出为csv时,如果数据阅读方是excel环境,为了兼容excel的读取问题,请使用以下方式导出:
1
df.to_excel(path, encoding=“utf_8_sig”)
其他部分都与普通用法一致,区别只有encoding参数选择utf_8_sig
可选参数的variable annotation
variable annotation可以增加我们代码的可读性,但是有的时候我们的默认值是None,和我们给定的类型不一致,这时候我们可以嵌套一层Optional,就不会被IDE diss啦,例如:
1
2
3
from typing import Optional
def do_something(a: int, b: Optional[int] = None):
pass
typing支持泛型
python中的类型提示是可以支持泛型的,核心概念可以搜索TypeVar
示例程序:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
# encoding: utf-8
from typing import TypeVar, List
T = TypeVar("T")
class A(object):
def __init__(self):
self.a = 1
class B(object):
def __init__(self):
self.b = 2
def get_first_one_1(origin_list):
return origin_list[0]
def get_first_one_2(origin_list: List[T]) -> T:
return origin_list[0]
def run():
a_list: List[A] = [A(), A()]
b_list: List[B] = [B(), B()]
print(get_first_one_1(a_list).a)
print(get_first_one_1(b_list).a)
print(get_first_one_2(a_list).a)
print(get_first_one_2(b_list).a)
if __name__ == '__main__':
run()
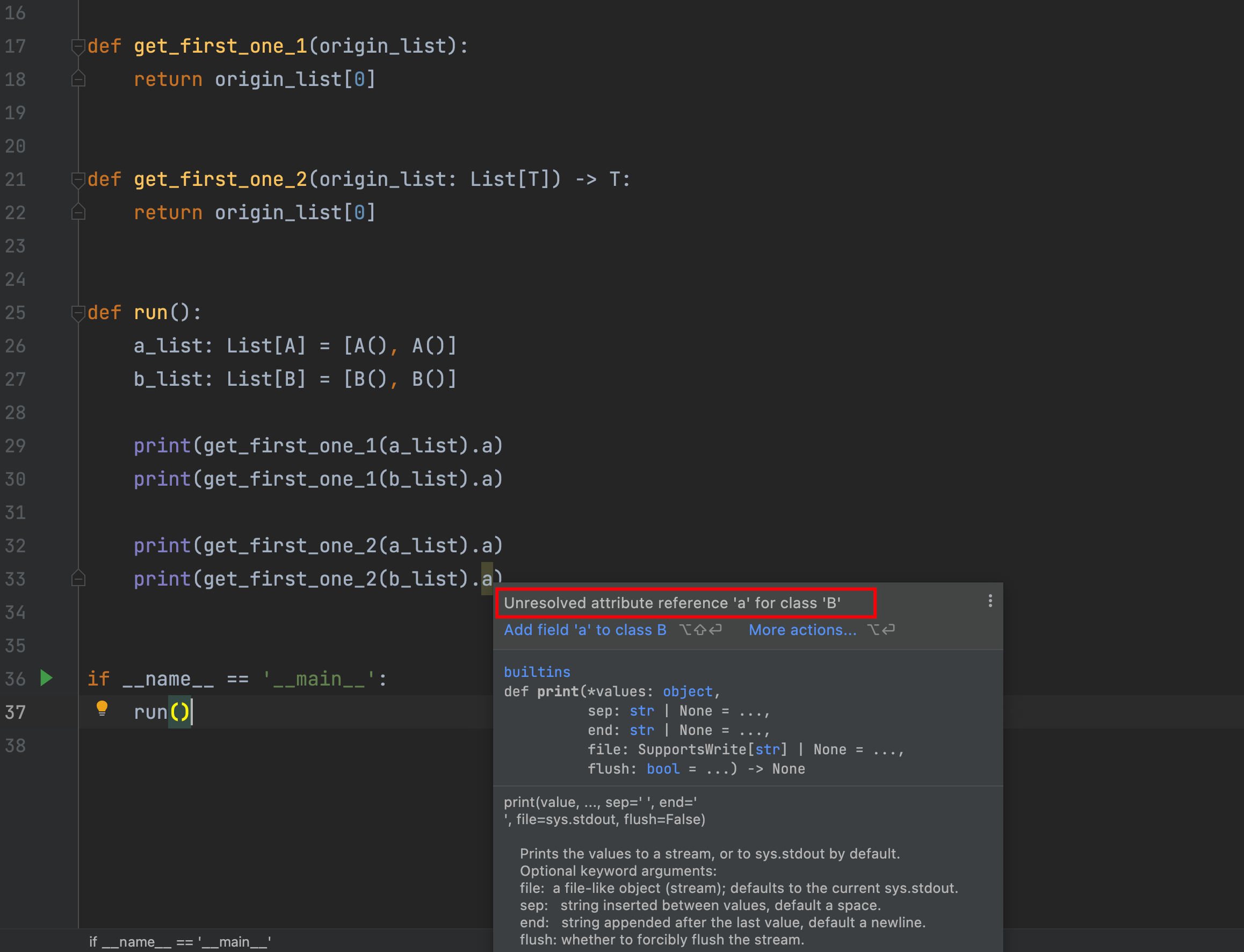
我们在这里定义了两个函数get_first_one_1和get_first_one_2,其中get_first_one_2使用了TypeVar
在run函数里,第30行和33行运行时会报错,但是30行不会提示,而33行则有提示,如截图:
type dict
TypedDict可以算是在dict和data_class中间的一个类,核心是既是dict的子类(因此可以用dict的表示和初始化)同时还有提示功能(输入了不支持的key会在IDE中提示),注意只是提示不是报错,如图:
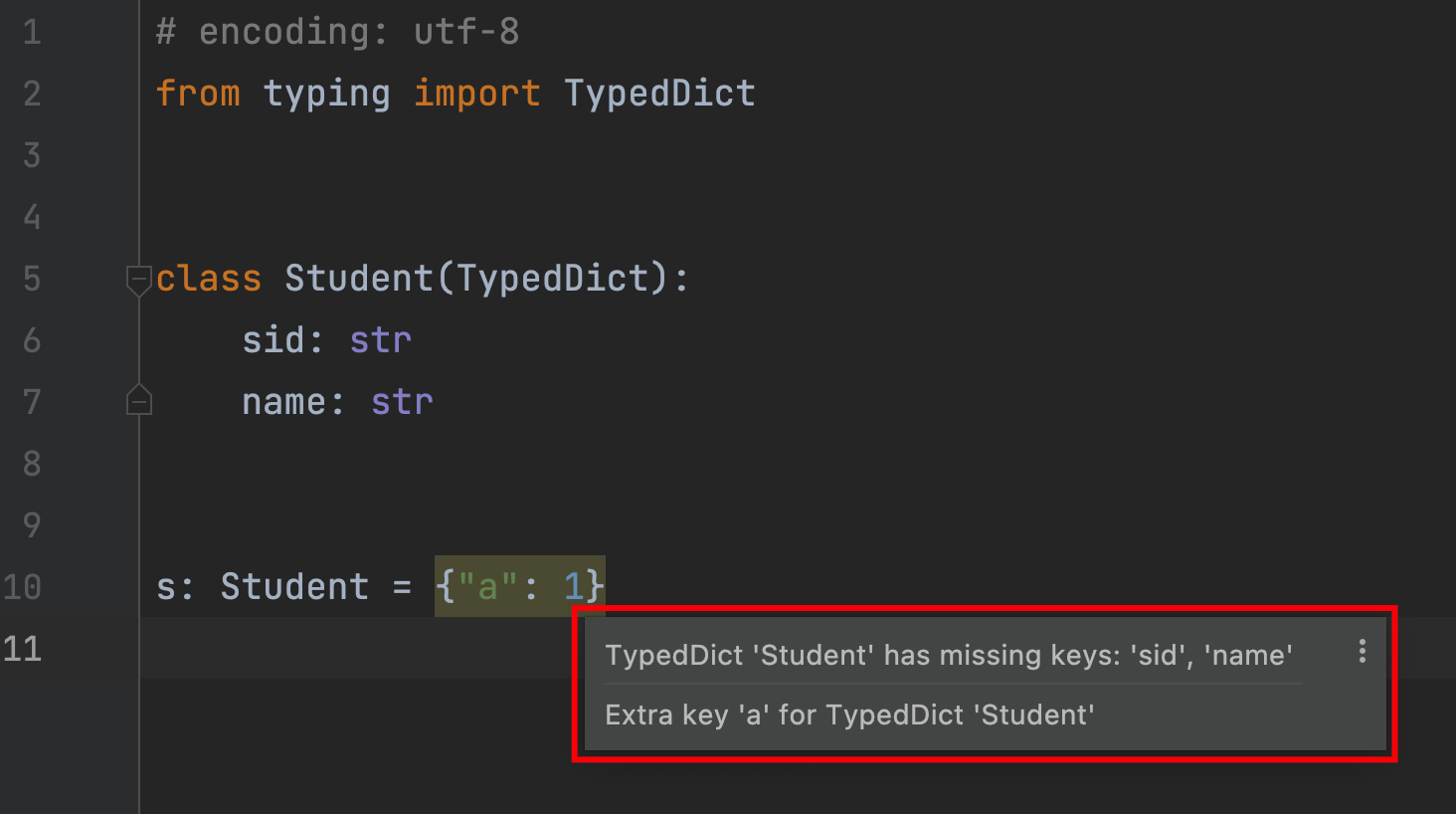
上面图里展示的代码虽然提示了报错,但是依旧是可以运行的。
ipython导出输入历史
我们有的时候利用ipython验证想法,结果越写越多想导出成python文件继续开发,或者单纯因为验证通过不想再输入一遍,可以使用下面的命令导出输入历史
1
%hist -f input_history.py
输出—-
在使用print的时候,我们有时会这样写:
1
2
title = "Hello World"
print("--------------" + title + "--------------")
或者尝试写的好看一点:
1
2
title = "Hello World"
print("-"*15 + title + "-"*15)
其实python自己本身是有这个函数的:
1
2
title = "Hello World"
print(title.center(50, "-"))